CARE-GNN
Enhancing Graph Neural Network-based Fraud Detectors against Camouflaged Fraudsters
Yingtong Dou1, Zhiwei Liu1, Li Sun2, Yutong Deng2, Hao Peng3, Philip S. Yu1
会议:CIKM '20
原文地址:https://dl.acm.org/doi/abs/10.1145/3340531.3411903
参考翻译:https://blog.csdn.net/jingcao233/article/details/121718108
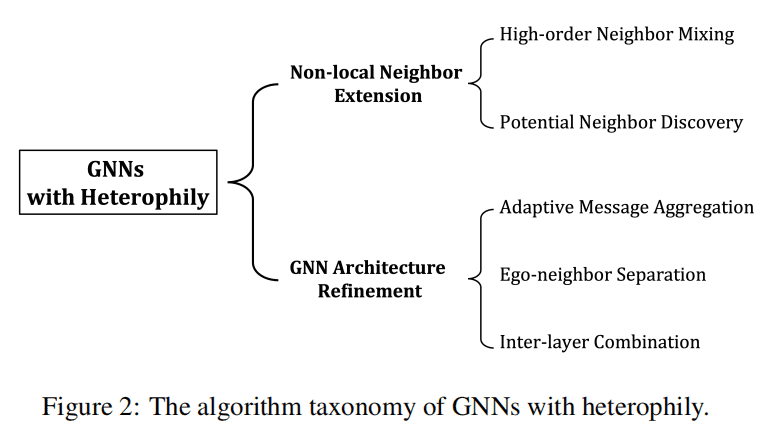
introduction
Graph-based methods can reveal the suspiciousness of these entities at the graph level, since fraudsters with the same goal tend to connect with each otherTextual features
GNN-based methods aggregate聚合 neighborhood information to learn the representation of a center node with neural modules. They can be trained in an end-to-end and semi-supervised fashion, which saves much feature engineering and data annotation cost.
motivation:
- ignoring the camouflage behaviors of fraudsters
- the limitations and vulnerabilities of GNNs when graphs have noisy nodes and edges
- Though some recent works have noticed similar challenges, either fail to fit the fraud detection problems or break the end-to-end learning fashion of GNNs
- Directly applying GNNs to graphs with camouflaged fraudsters will hamper the neighbor aggregation process of GNNs.
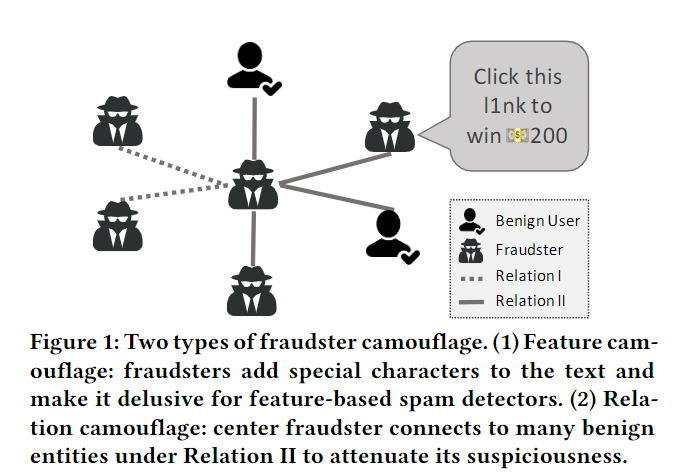
two types of camouflages:
- Feature camouflage: fraudsters may ==adjust their behaviors==, add special characters in reviews, or employ deep language generation models to gloss over explicit suspicious outcomes
- Relation camouflage: fraudsters camouflage themselves via ‘connecting to many benign entities’
method:
- For the feature camouflage: label-aware similarity measure to find the most similar neighbors based on node features. Specifically, we design a neural classifier as a similarity measure, which is directly optimized according to experts with domain knowledge (i.e., annotated data).基于标签感知的相似性度量计算其邻居相似性
- For the relation camouflage: devise a similarity-aware neighbor selector to select the similar neighbors of a center node within a relation. Furthermore, we leverage reinforcement learning (RL) to adaptively find the optimal neighbor selection threshold along with the GNN training process.
- We utilize the neighbor filtering thresholds learned by RL to formulate a relation-aware neighbor aggregator which combines neighborhood information from different relations and obtains the final center node representation获得中心节点表示
advantages & benefits:
- Adaptability. CARE-GNN adaptively selects best neighbors for aggregation given arbitrary multi-relation graph.
- High-efficiency. CARE-GNN has a high computational efficiency without attention and deep reinforcement learning.
- Flexibility. Many other neural modules and external knowledge can be plugged into the CARE-GNN
steps:
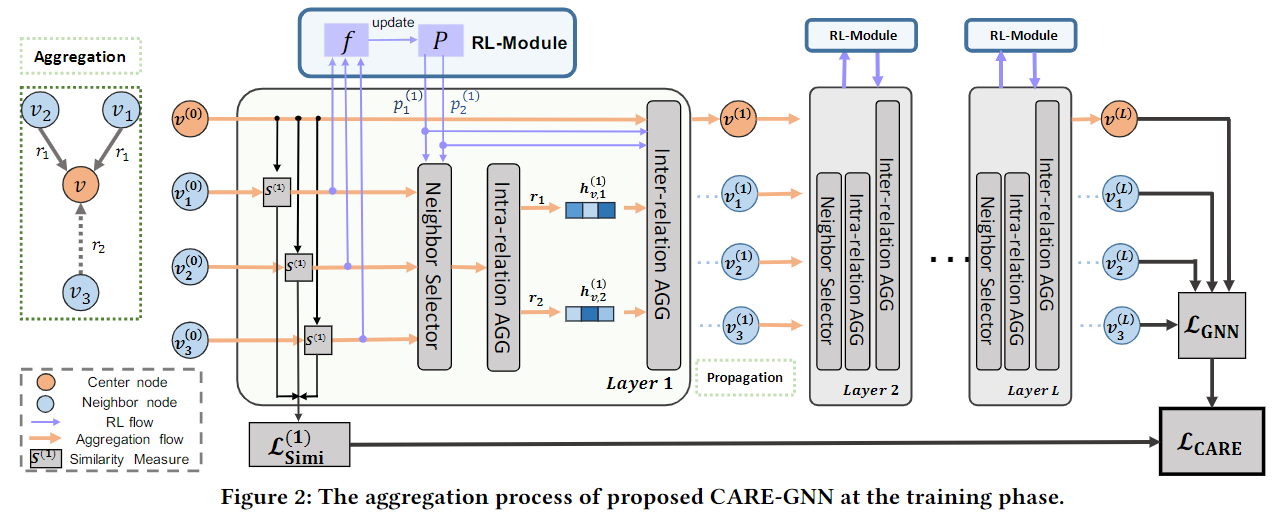
- construct a multi-relation graph based on domain knowledge.
- first compute its neighbor similarities based with proposed
label-aware similarity
measure.基于标签感知的相似性度量计算其邻居相似性,通过对比节点特征来寻找最相似的邻居。
- high time complexity×
- employ a one-layer MLP as the node label predictor at each layer and
use the l1-distance between the prediction results of two nodes as their
similarity
measure.在每一层采用一层MLP作为节点标签预测器,并使用两个节点预测结果之间的距离作为它们的相似性度量
- Optimization. To train the similarity measure together with GNNs, a heuristic approach is to append it as a new layer before the aggregation layer of GCN [ 20 ]. However, if the similarity measure could not effectively filter the camouflaged neighbors at the first layer, it will hamper the performance of following GNN layers. Consequently, the MLP parameters cannot be well-updated through the back-propagation process. To train the similar measure with a direct supervised signal from labels, like [ 35], we define the cross-entropy loss of the MLP at l-layer asv the similarity measure parameters are directly updated through the above loss function.为了与gnn一起训练相似性度量,一种启发式的方法是在GCN[20]的聚合层之前添加一个新的层。但是,如果相似性度量不能有效地过滤第一层的伪装邻居,则会影响后续GNN层的性能。因此,MLP参数不能通过反向传播过程很好地更新。为了用来自标签的直接监督信号(如[35])训练相似度量,我们定义了l层MLP的交叉熵损失,因为相似度量参数直接通过上述损失函数更新。
- Similarity-aware Neighbor Selector:Then filter the dissimilar
neighbors under each relation with the proposed neighbor
selector.相似度感知的邻居选择器:使用邻居选择器过滤每个关系下的不同邻居:选择一个中心节点的某个关系下的相似邻居。另外,在训练过程中,使用强化学习(RL)自适应地找到最佳邻居选择阈值
- It selects similar neighbors under each relation using top-p sampling with an adaptive filtering threshold.它使用具有自适应滤波阈值的top-p采样在每个关系下选择相似的邻居。
- formulate the RL process as B(A,f,T).A是action space,f是reward
function,T是terminal condation. an initial pr(l)初始阈值
- action: The action represents how RL updates the pr(l) based on the reward
- reward: The optimal pr(l) is expected to find the most similar (i.e.,minimum distances in Eq.
- define the reward for epoch e as:epoch e的奖励定义为:
当epoch e ee上新选择的邻居的平均距离小于前一个epoch时,奖励为正,反之为负。但估计累加奖励并不容易,因此设计了无需搜索的贪婪策略,使用即时奖励来更新动作。
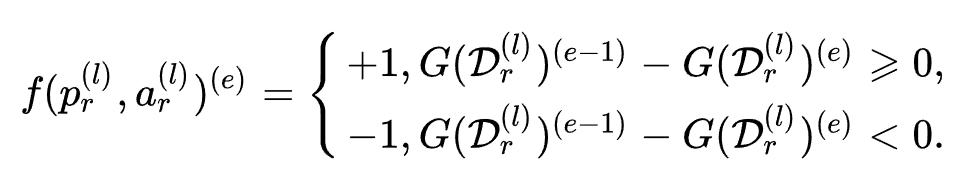
- 终止条件:
- RL在最近的10个epoch收敛,并发消息最优阈值。 RL模块终止后,过滤阈值固定为最优阈值,直到GNN收敛。
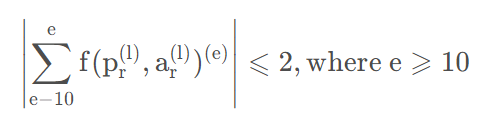
- Then, the GNN is trained with partially labeled nodes supervised by binary classification loss functions. The neighbor selector is optimized using reinforcement learning during training the GNN.用二元分类损失函数,使用部分标记节点进行监督训练。训练期间使用强化学习优化邻居选择器:构造一个关系感知的邻居聚合器,该聚合器将来自不同关系的邻居信息结合起来,得到最终的中心节点表示。
- Instead of directly aggregating the neighbors for all relations, we
separate the aggregation part as intra-relation aggregation关系内聚合
and inter-relation aggregation关系间聚合 process. During the
intra-relation aggregation process, the embedding of neighbors under
each relation is aggregated simultaneously. Then, the embeddings for
each relation are combined during the inter-relation aggregation
process.
intra-relation neighbor aggregation:
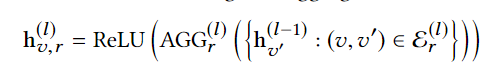
inter-relation aggregation:
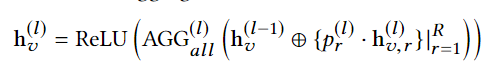
- Finally, the node embeddings at the last layer are used for prediction.
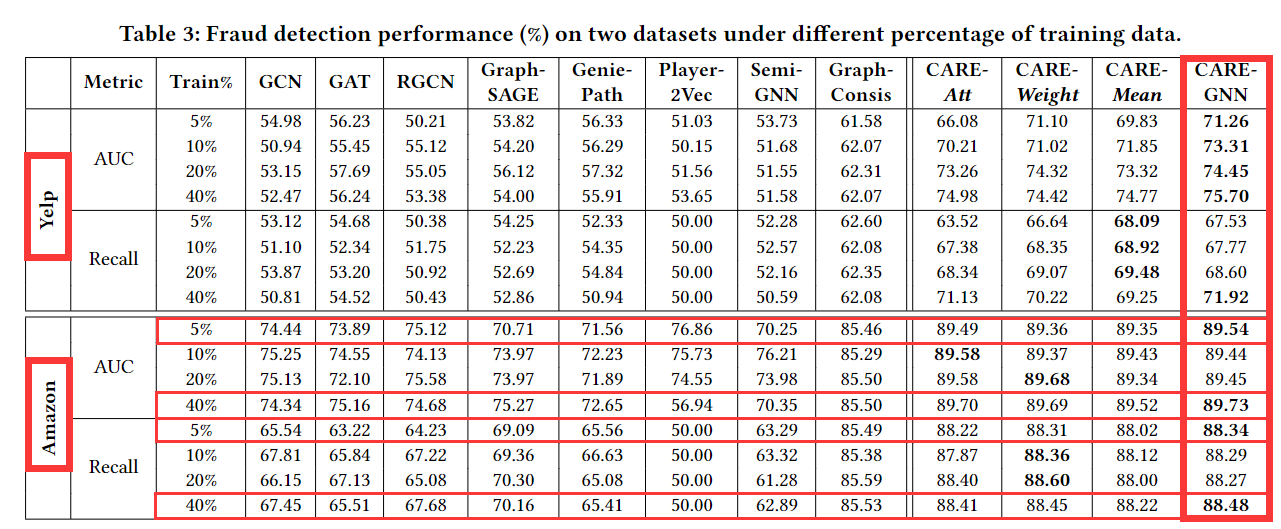
做出了两个数据集
存在问题:
mlp预测不准的话,会删掉很重要的或者良性的边。
两种相差很大的benign,互相对对方的学习有帮助
直接删掉会对模型有很大问题
Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks
HAO PENG∗, Beihang University, China
RUITONG ZHANG, Beihang University, China
YINGTONG DOU, University of Illinois at Chicago, USA
RENYU YANG, University of Leeds, UK
JINGYI ZHANG, Beihang University, China
PHILIP S. YU, University of Illinois at Chicago, USA
Alleviating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection
Zhiwei Liu, Yingtong Dou, Yutong Deng, Hao Peng
the inconsistency problem incurred by fraudsters is hardly investigated
《Alleviating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection》阅读笔记
Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection
在sample子图的时候尽可能地选minority点,在构造邻居的时候尽可能增大minority的邻居,减少majority的邻居
他们专注于修改邻接矩阵来修剪噪声边缘或保持一个平衡的邻域标签频率,
Rethinking Graph Neural Networks for Anomaly Detection
ICML 2022 | 基于结构化数据的异常检测再思考: 我们究竟需要怎样的图神经网络?
【GNN报告】香港科技大学李佳:图异常检测再思考-我们究竟需要怎样的图神经网络?-pudn.com