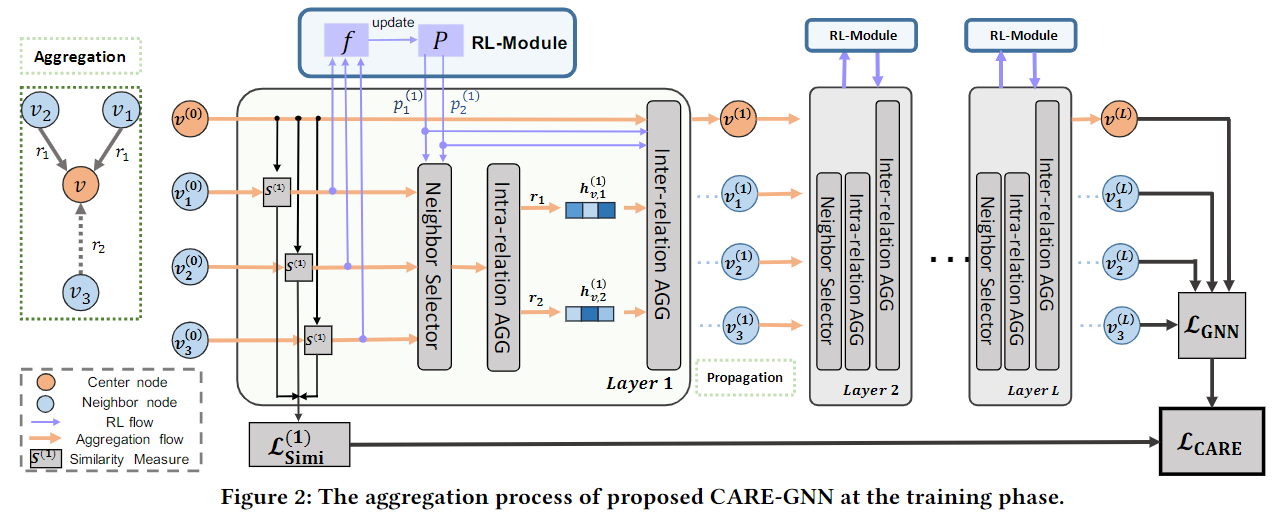
Graph Transformers
一些关于transformer
cls:classification,用于下游的分类任务。CLS就是一个向量,只是不是某一个字的向量,是一个够代表整个文本的的语义特征向量,取出来就可以直接用于分类了。实际场景:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等
BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
RNN的两个明显问题:

效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理
如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题
LSTM、GRU的改进属于换汤不换药。
为解决这些问题,设计的Transformer是一个N进N出的结构,每个Transformer单元相当于一层的RNN层,接收一整个句子所有词作为输入,然后为句子中的每个词都做出一个输出。但是与RNN不同的是,Transformer能够同时处理句子中的所有词,并且任意两个词之间的操作距离都是1,很好地解决了上面提到的RNN的效率问题和距离问题。

decoder比encoder多了一共attention,用于接受encoder的输出:
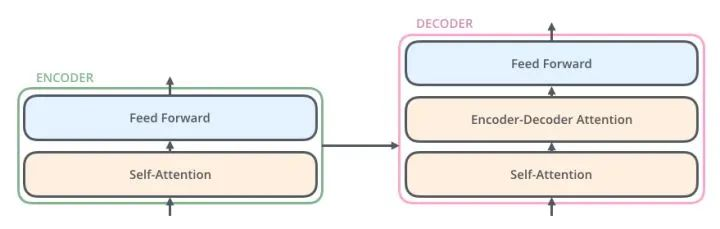
详细结构:

encoder的输入包含两个,是一个序列的token embedding + positional embedding
self-attention层:句子中的某个词对于本身的所有词做一次Attention,算出每个词对于这个词的权重,然后将这个词表示为所有词的加权和。
首先,每个词都要通过三个矩阵\(W_q\), \(W_k\), \(W_v\)进行一次线性变化,一分为三,生成每个词自己的query, key, vector三个向量。以一个词为中心进行Self Attention时,都是用这个词的key向量与每个词的query向量做点积,再通过Softmax归一化出权重。通过这些权重算出所有词的vector的加权和,作为这个词的输出。(通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。)
self-attention的特点在于无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并且可以并行计算。从一些论文中看到, self-attention可以当成一个层和RNN,CNN,FNN等配合使用,成功应用于其他NLP任务。

归一化之前需要通过除以向量的维度dk来进行标准化,所以最终Self Attention用矩阵变换的方式可以表示为: \[ Q=XW_Q\\ K=XW_K\\ V=XW_V\\ Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}})V \] 上文提到Encoder中的Self Attention与Decoder中的有所不同,Encoder中的Q、K、V全部来自于上一层单元的输出,而Decoder只有Q来自于上一个Decoder单元的输出,K与V都来自于Encoder最后一层的输出。也就是说,Decoder是要通过当前状态与Encoder的输出算出权重后,将Encoder的编码加权得到下一层的状态。
Multi-head-attention:Multi-Head Attention就是将上述的Attention做h遍,然后将h个输出进行concat得到最终的输出。这样做可以很好地提高算法的稳定性,在很多Attention相关的工作中都有相关的应用。Transformer的实现中,为了提高Multi-Head的效率,将W扩大了h倍,然后通过view(reshape)和transpose操作将相同词的不同head的k、q、v排列在一起进行同时计算,完成计算后再次通过reshape和transpose完成拼接,相当于对于所有的head进行了一个并行处理。
Masked-attention:Encoder要编码整个句子,所以每个词都要考虑上下文的关系。所以每个词在计算的过程中都是可以看到句子中所有的词的。但是Decoder与Seq2Seq中的解码器类似,每个词都只能看到前面词的状态,所以是一个单向的Self-Attention结构。Masked Attention的实现也非常简单,只要在普通的Self Attention的Softmax步骤之前,与(&)上一个下三角矩阵M就好了 \[ Attention(Q,K,V)=Softmax(\frac{QK^T \odot M}{\sqrt{d_k}})V \]
Position-wise Feed Forward Networks:Encoder中和Decoder中经过Attention之后输出的n个向量(这里n是词的个数)都分别的输入到一个全连接层中,完成一个逐个位置的前馈网络。
- FFN是两层全连接。这里使用FFN层的原因是:为了使用非线性函数来拟合数据。如果说只是为了非线性拟合的话,其实只用到第一层就可以了,但是这里为什么要用两层全连接呢,是因为第一层的全连接层计算后,其维度是(batch_size, seq_len, dff)(其中dff是超参数的一种,设置为2048),而使用第二层全连接层是为了进行维度变换,将dff转换为初始的d_model(512)维。
\[ FFN(x)=max(0,xW_1+b_1)W_2+b_2 \]
Add & Norm:是一个残差网络,将一层的输入与其标准化后的输出进行相加即可。Transformer中每一个Self Attention层与FFN层后面都会连一个Add & Norm层。该层是为了对attention层的输出进行分布归一化,转换成均值为0方差为1的正态分布。cv中经常会用的是batchNorm,是对一个batchsize中的样本进行一次归一化,而layernorm则是对一层进行一次归一化,二者的作用是一样的,只是针对的维度不同,一般来说batchnorm的输入维度是(batch_size, seq_len, embedding),针对的是batch_size层进行处理,而layernorm则是对seq_len进行处理(即batchnorm是对一批样本中进行归一化,而layernorm是对每一个样本进行一次归一化)。使用ln而不是bn的原因是因为输入序列的长度问题,每一个序列的长度不同,虽然会经过padding处理,但是padding的0值其实是无用信息,实际上有用的信息还是序列信息,而不同序列的长度不同,所以这里不能使用bn一概而论。
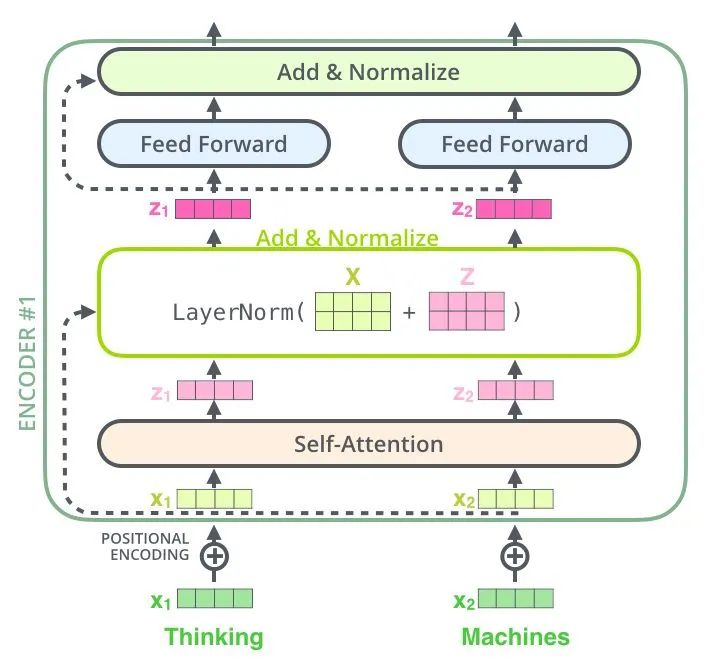
Positional Encoding:Transformer中句子里的所有词都被同等的看待,所以词之间就没有了先后关系,很可能会带上和词袋模型相同的不足。因此,需要给每个输入的词向量叠加一个固定的向量来表示它的位置 \[ PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})\\ PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) \] pos是词在句子中的位置,i是词向量中第i位,即将每个词的词向量为一行进行叠加,然后针对每一列都叠加上一个相位不同或波长逐渐增大的波,以此来唯一区分位置。
GPT(Generative Pre-Training),是OpenAI在2018年提出的模型,利用Transformer模型来解决各种自然语言问题,例如分类、推理、问答、相似度等应用的模型。GPT采用了Pre-training + Fine-tuning的训练模式,使得大量无标记的数据得以利用,大大提高了这些问题的效果。
- Decoder Block中使用的是Masked Self-Attention,即句子中的每个词,都只能对包括自己在内的前面所有词进行Attention,这就是单向Transformer。GPT使用的Transformer结构就是将Encoder中的Self-Attention替换成了Masked Self-Attention
关系归纳偏置(relational inductive biases)
讲解一些编码:https://blog.csdn.net/zjc910997316/article/details/121524624
https://blog.csdn.net/qq_38253797/article/details/127620115
https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247493785&idx=3&sn=5730ed0d277e049f31880a0ceba7629f&chksm=ebb7d04ddcc0595bd9b38659832f8c8b681d374fe29108337e491a3c6d60b3a4fa873939294b&scene=27
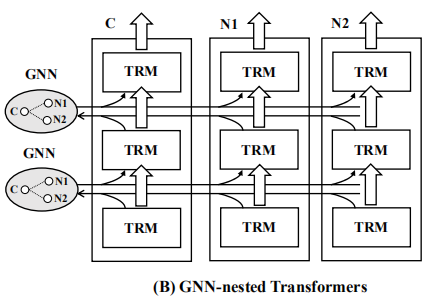
Graph-Formers: GNN-nested Transformers for Representation Learning on Textual Graph
from NIPS 2021, code
Motivation:
文本图上的表示学习是基于单个的文本特征和邻域信息为节点生成低维embeddings。现有的方法主要依赖于cascaded model architecture:节点的textural features首先由语言模型独立编码;textural embeddings再通过GNN进行聚合。但是由于对textural features的独立建模,上述体系结构受到了限制。
本文提出的GraphFormers中,GNN组件按层嵌套在the transformer blocks of language models旁边,使用该框架后,text encoding和graph aggregation are fused into and iterative workflow,从全局的角度准确地理解每个节点的语义(semantic)。
另外,还是用了一个progressive learning strategy,通过对操作数据(manipulated data)和原始数据(original data)进行连续(successively)训练,增强模型对图上信息的整合能力。
Intro:
目前的主流方法是Pre-trained Language Representation(PLM,例如BERT,获得文本的底层语义)结合GNN(聚合邻域信息,获得more informative的embeddings)。这种组合方式叫做Cascaded Transformers-GNN,因为transformers部署在GNN前面, 。但是,考虑到linked nodes是相互关联的,在生成embedding时,其底层语义可以相互增强。例如,给定一个节点“notes on transformers”和他的邻居的“tutorials on machine translation”,通过参考整个上下文,这里的“transformers”可以被解释为一个机器学习模型,而不是一个电子设备变压器。
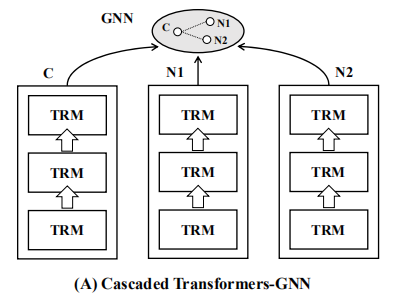
在本文中,文本编码(transformerer layers)和图聚合(GNN)迭代进行,在每个迭代后,linked nodes在layerwise的GNN组件中相互交换信息;因此,每个节点都将被其邻域信息增强(在这里可以使用异质性?)。然后transformer在增强的节点特征上work,这个节点特征可以为下一次迭代生成信息更丰富的节点表示。与级联架构相比,GraphFormers图上的cross-node information进行了更充分的利用,大大提高了表示质量。考虑到分层的GNN组件只涉及简单和有效的multi-head attention,GraphFormers保持了与现有的级联模型相当的运行成本。
训练过程中:
Method
每个节点x都是一个text,节点x及其相邻节点\(N_x\)记为\(G_x\)。模型基于节点x的文本特征和他的邻域信息来学习嵌入。生成的嵌入被期望捕获节点之间的关系,即基于嵌入的相似度准确地预测两个节点是否是而进行连接的。
关于token embedding,
model simplification
训练任务是链路预测
GraphTrans: Representing Long-Range Context for Graph Neural Networks with Global Attention
graph classification task(text-classification)
CLS:
将图输入GNN获得图中每个节点的向量表示(让节点的向量表示获取位置信息),之后将每个节点的向量表示输入标准的Transformer(将自然语言处理中的CLS作为一种readout机制引入图分类)
在节点序列的首位置加入一个CLS节点(因为使用的Transformer不带positional encoding,所以CLS的位置可以随意选取),之后使用经过Transformer的CLS表示进行图分类任务。
实质上,CLS readout可以做是virtual node的generalization或者deep version.(This special-token readout mechanism may be viewed as a generalization or a “deep” version of a virtual node readout.但是virtual node method不允许学习图节点之间的成对关系,除了在虚拟节点的嵌入内)
GraphGPS: Recipe for a General, Powerful, Scalable
对现有的PE(positional emcodings)和SE(structural encodings)进行分类
各自作用:PE gives a notion of distance, while SE gives a notion of structural similarity.
One can always infer certain notions of distance from large structures, or certain notions of structure from short distances, but this is not a trivial task, and the objective of providing PE and SE remains distinct.
PE是为了提供图中给定节点在空间中的位置的概念。因此,当在图或子图中两个节点彼此接近时,它们的PE也应该接近。一种常见的方法是计算每对节点或其特征向量之间的pair-wise distance,但这与Transformer器不兼容,因为它需要实现full attention matrix。相反,我们希望PE是节点或者边的特征,因此,一个更好的拟合解是使用图的拉普拉斯矩阵的特征向量或它们的梯度。
SE旨在提供图或子图结构的embedding,以提高GNN的expressivity and the generalizability。因此,当两个节点共享相似的子图时,或者当两个图相似时,它们的SE也应该很接近。简单的方法是将图中的pre-defined patterns识别为一个热编码,但它们需要对图的专家知识。
这些编码如何增加MPNNs的表达
参考链接:
https://blog.csdn.net/yeen123/article/details/125104680
https://zhuanlan.zhihu.com/p/604450283