动态图异常检测数据集,及GearSage代码详解
传统意义的时序异常检测
随着车辆、工业系统和数据中心等网络物理系统(CPS)中的互联设备和传感器的快速增长,监测这些设备的需求越来越大以保护他们免受攻击。对于电网、水处理厂、交通和通信网络等关键基础设施尤其如此。
许多这样的现实世界系统涉及到大量的相互连接的传感器,这些传感器可以产生大量的时间序列数据。例如,在一个水处理厂中,可以有许多传感器测量其各部件中的水位、流量、水质、阀门状态等。来自这些传感器的数据可以以复杂的、非线性的方式联系起来:例如,一个阀门导致压力和流量的变化,导致进一步的变化,因为自动机制响应变化的变化。随着这种传感器数据的复杂性和维度的增长,人类手动监控这些数据的能力越来越低。
研究时序变化的图结构的异常检测
| Dataset | #Node | #Edge | Edge Type | Max. Degree | Avg. Degree | #Timestamp | Paper |
|---|---|---|---|---|---|---|---|
| UCI Message1 | 1899 | 13838 | directed、unweighted、inject anomalies | 255 | 14.57 | 190 | AddGraph、DynAD、Hierarchical、StrGNN |
| Digg | 30360 | 85155 | 283 | 5.61 | 16 | AddGraph、DynAD、StrGNN | |
| arXiv hep-th | 6798 | 214693 | 1590 | 63.16 | DynAD | ||
| Enron2 | 87036 | 530284 | direcetd、unweighted、inject anomalies | 1150 | 22 | Hierarchical | |
| Facebook3 | 60730 | 607487 | undirected、unweighted、inject anomalies | 203 | 9 | Hierarchical | |
| Math4 | 24740 | 323357 | directed、unweighted、inject anomalies | 231 | 15 | Hierarchical | |
| 2029 | 3724 | 20 | StrGNN | ||||
| Topology | 34761 | 107661 | 21 | StrGNN | |||
| Bitcoin-alpha | 3783 | 14124 | 63 | StrGNN | |||
| Bitcoin-otc | 5881 | 21492 | 63 | StrGNN |
- UCI Message:a directed network,其中包含了在加州大学欧文分校的一个在线社区中发布的信息,每个节点代表一个用户,每个有向边代表两个用户之间的一条消息
- Digg:社交新闻网站Digg旗下的一个响应网络。网络中的每个节点都是站点的用户,每条边都表示一个用户回复另一个用户。
这两个数据集中的边都用时间戳进行了注释,在AddGraph5(使用)中,作者为每个节点随机生成一个初始向量作为其内容特征。
- arXiv:来自e-print arXiv的collaboration network,节点和边分别表示作者和协作链接。
- Enron:Enron公司的电子邮件数据集包含了大约50万封由安然公司的员工生成的电子邮件。美国联邦能源管理委员会在调查安然公司倒闭期间获得了这些电子邮件。
- Facebook:无向网络包含了Facebook用户的友谊数据。一个节点表示一个用户,一条边表示两个用户之间的友谊数据。该数据集并不完整,它包含了整个脸书友谊图中的一小部分子集。
- Math:这是一个在stack exchange网站Math Overflow上的时间交互网络,不同类型的边表示不同的交互关系。
hierarchical GNN6使用伯努利分布注入不同比例的异常,然后将数据集分成两半分别作为训练集和测试集
- Email:是民主党全国委员会的电子邮件。每个节点对应于一个人,边表示两个人之间的电子邮件交流。
- Topology:互联网自治系统之间的网络连接。节点是自治系统,边是自治系统之间的连接。
- Bitcoin-alpha和Bitcoin-otc:分别来自两个比特币平台Alpha和OTC,节点表示来自该平台的用户,如果一个用户对平台上的另一个用户进行评级,则在他们之间存在一条边。
DGraph数据集
信也科技杯图算法大赛、Github地址、DGraph论文openreview(含appendix)
大小是Elliptic的17倍,动态图上的节点异常检测,贴近工业背景
node attribute、node feature、edge weight、timestamp of the edge
File dgraphfin.npz including below keys: |
节点的出度表示信息完整度(可自控),入度表示被信任关系(不可自控)
统计:一个有label的节点他周围的节点是有label多的还是没有label的多
有向图->邻接矩阵,邻接链表->筛选出label=0,1的节点->
首先用dict得到每个节点的入度和出度个数
- 有向图的节点出度数和入度数相等,先得到图中所有定点的平均度数:1.1622593938738837
- 正常节点有1210092个,其邻居中正常的有1277944个,欺诈的有9370个,bg2有1176560个,bg3有701840个。
- 异常节点有15509个,其邻居中正常的有9370个,欺诈的有424个,bg2有12657个,bg3有6527个。
在GearSage的处理方法中(与PyG的方法不同):
原来的npz文件:['x', 'y', 'edge_index', 'edge_type', 'edge_timestamp', 'train_mask', 'valid_mask', 'test_mask’]
处理后的data.pt:Data(x=[3700550, 31], edge_index=[2, 4300999], edge_attr=[4300999], y=[3700550, 1], train_mask=[857899], test_mask=[183840], valid_mask=[183862], edge_timestamp=[4300999])
对数据集的处理:read_dgraphfin(folder)
- 增加节点入度——dim=1。将节点入度作为新加入的一列
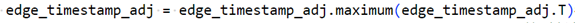
- 邻域时间戳信息——dim=2。构建edge_timestamp的邻接矩阵,增加edge_timestamp_sum(每个节点连边的时间戳的总和,然后normalize)和edge_timestamp_max(先增加反向边,然后求该节点相邻边的最大时间戳,并log)
- 边属性信息——dim=11。构建edge_attr的邻接矩阵,获取与当前节点相连的边中,不同类型的边的数量。
节点特征工程
- 增加节点度数——dim=2。将节点的入度和出度作为新的特征
- 与邻域的相似度信息——dim=1。(将相邻节点的cosine similarity作为新的特征)
- 处理缺失值。将初始的17维节点特征中的缺失值-1替换为1
- 前景、背景节点信息——dim=2
边特征工程
- 加入反向边增加图稠密度——此时的图不一定是对称的,因为正向和反向边的时间戳不一定一样,但是type是一样的
- 构建边的方向性信息:
- 先把原来的edge_index的row和col各自concat,然后选择里面row小于col的边保留,
tips:
1、temp = scatter.scatter(a, row, dim=0, dim_size=y.size(0), reduce="sum")
torch_scatter.scatter(src: torch.Tensor, index: torch.Tensor, dim: int = - 1, out: Optional[torch.Tensor] = None, dim_size: Optional[int] = None, reduce: str = 'sum') → torch.Tensor |
根据index,将index相同值对应的src元素进行对应定义的计算,dim为在第几维进行相应的运算。e.g.scatter_sum即进行sum运算,scatter_mean即进行mean运算。
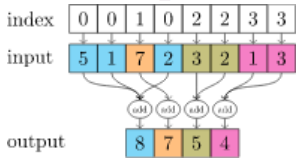
在gear的处理过程中,对于a = F.one_hot(y[col]),按照row,也就是边的src节点,把src节点相同的边的dst节点的one
hot相加,输出的尺寸是[节点个数,2],表示src所连dst节点的背景和前景节点情况。
接着,temp += scatter.scatter(b, col, dim=0, dim_size=y.size(0), reduce="sum")又将每个dst节点对应的src的one
hot相加。
两个temp相加后,得到的是每个节点所连边(from+to)的节点背景节点的数量
增量学习和对邻域信息做衰减是什么?